OpenType Features»
Support for OpenType layout features in FontLab is based on technologies provided by Adobe – one of OpenType’s two inventors and key supporters. Like many font tools, FontLab uses Adobe’s AFDKO feature description language for the text representation of OpenType features, which are then compiled into OpenType code.
FontLab handles OpenType layout features in the Features panel — see that for general information on managing features; this section discusses in detail the coding that goes in the right-hand side of that panel.
Layout features may refer to glyph classes and kerning classes (used in the kern feature). Both these need to be defined in the Classes panel.
FontLab’s OpenType support consists of three stages:
-
Importing OpenType fonts and reading the binary OpenType tables. FontLab stores the original binary (compiled) tables in the .vfc file and also interprets (decompiles) the binary tables into FontLab’s internal (AFDKO-based) feature definition format. Preference settings control whether the original binary tables are maintained at file open time, and/or whether the binary tables are interpreted for further editing.
-
Editing the features and previewing the results. FontLab provides a feature editor that is integrated into the FontLab user interface in the form of the Features panel. Features are also integrated with the Glyph Window and Preview panel, so you can see whether and how features work without actually exporting and installing the font file.
-
Feature compilation and export. The Adobe FDK for OpenType (AFDKO) library is used to compile the feature definitions into binary tables and build the OpenType font files. FontLab VI supports a newer version of AFDKO than FontLab Studio 5 did, so a full range of positioning (GPOS) lookups are supported.
Substitution Lookups»
Substitution lookups deal with the replacement of one or more target glyph(s) with one or more replacement glyph(s). This replacement can be one-to-one, one-to-many, or many-to-one. Substitutions are stored in the GSUB table in a compiled OpenType font.
The OpenType specification declares the following types of basic substitutions:
| Single substitution | Replaces a single glyph with another single glyph: a → A |
| Ligature substitution | Replaces multiple glyphs with a single glyph: f l → |
| Multiple substitution | Replaces a single glyph with multiple glyphs: $ → d o l l a r |
| Alternate substitution | Replaces a single glyph with one of several glyphs chosen from a list: A → A.version1 or A.version2 |
All these substitutions may be context independent or context-dependent. Context-independent lookups are applied every time the correct sequence of source glyphs is present, like when you want to replace the ‘f’ and ‘l’ sequence with the ‘fl’ ligature. In other cases you may need to apply a substitution only when a source sequence of glyphs is surrounded by some other glyphs; this is context-dependent substitution. For instance, you may want to replace a ‘p’ with a variant with a swashy descender, but only when it is followed by another lowercase character that has no descender.
Single Substitution»
A single substitution is the simplest kind of substitution – it replaces a single glyph with another glyph, either directly or by using classes. You can replace a glyph or a member of a class, with another glyph or a member of another class. To replace members of one class with another, it is required that the number of glyphs in the target and replacement classes be the same.
A single substitution rule is specified in one of the following formats, where the keyword sub is short for substitute:
sub <glyph> by <glyph>; # format A
sub <glyphclass> by <glyph>; # format B
sub <glyphclass> by <glyphclass>; # format CFormat A specifies that the target glyph will be substituted by the replacement glyph. Following is an example:
sub a by a.smcp; # format A Format B specifies that if any glyph from the target class is encountered, it will be substituted by the replacement glyph. An example is described below:
sub [one.fitted one.onum one.taboldstyle] by one; # format B Format C specifies that each glyph in the target glyph class must be replaced by its corresponding glyph (in the order of glyphs in the glyph classes) in the replacement glyph class. If the replacement is a singleton glyph class, then the rule will be treated identically to a format B rule. If the replacement class has more than one glyph, then the number of elements in the target and replacement glyph classes must be the same.
For example:
sub [a - z] by [a.smcp - z.smcp]; # format C
sub @Capitals by @CapSwashes; # format CThe first line in the example above produces the same effect in the font as:
sub a by a.smcp;
sub b by b.smcp;
sub c by c.smcp;
...
sub z by z.smcp;Format C type substitutions can be used to replace different types of figures or to replace lowercase glyphs with small-caps:
sub @figs_lnum by @figs_onum;sub @lc by @sc;Ligature Substitution»
The ligature substitution rule replaces several glyphs in sequence with a single glyph.
A ligature substitution rule is specified as:
sub <glyph sequence> by <glyph>; <glyph sequence> must contain two or more <glyph|glyphclass>es. For example:
sub [one one.onum] [slash fraction] [two two.onum] by onehalf;Since the OpenType specification does not allow ligature substitutions to be specified on target sequences that contain glyph classes, at compile time FontLab will enumerate all specific glyph sequences if glyph classes are detected in <glyph sequence>. Thus, the above example produces the same effect in the font as if the font editor manually enumerated all the sequences:
sub one slash two by onehalf;
sub one.onum slash two by onehalf;
sub one fraction two by onehalf;
sub one.onum fraction two by onehalf;
sub one slash two.onum by onehalf;
sub one.onum slash two.onum by onehalf;
sub one fraction two.onum by onehalf;
sub one.onum fraction two.onum by onehalf;Note
Variant glyphs should be named just like their default counterparts, but with a suffix appended after a period. The suffix is usually the feature tag for the layout feature the variant glyph will be most likely accessed with. So, a small cap a can be named a.smcp and an old-style digit 2 can be named two.onum. Non-standard names should be avoided. For an extensive discussion about devising custom glyph names in OpenType fonts, refer to the Glyph Naming and Encoding section.
Almost all fonts contain at least two ligatures: f_l and f_i which can be easily coded in OpenType as:
sub f l by f_l;
sub f i by f_i;Some fonts add longer ligatures:
sub f f i by f_f_i;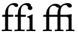
Note
Ligature glyphs should be named using the underscore rule, e.g. f_f_odieresis for an ffö ligature. Only the fi and fl ligatures should be named without the underscores. For an extensive discussion about devising custom glyph names in OpenType fonts, refer to the Glyph Naming and Encoding section.
A contiguous set of ligature rules does not need to be ordered in any particular way by the font editor; the implementation software does the appropriate sorting. So:
sub f f by f_f;
sub f i by fi;
sub f f i by f_f_i;
sub o f f i by o_f_f_i;will do the same thing as:
sub o f f i by o_f_f_i;
sub f f i by f_f_i;
sub f f by f_f;
sub f i by fi;Multiple Substitution»
Multiple substitution replaces one glyph with a sequence of glyphs.
A multiple substitution rule is specified as:
sub <glyph> by <glyph sequence>; For example, to convert a f_i ligature back into f and i you would do this:
sub f_i by f i;Classes cannot be used in multiple substitutions.
Alternate Substitution»
Alternate substitution replaces a glyph with one of the glyphs in a pre-defined list of alternatives. The application that uses the font is expected to decide which glyph to choose. A good example of this lookup is to provide several versions of some glyph, like the ampersand. Another application is the selection of several different forms of ornaments.
An alternate substitution rule is specified as:
sub <glyph> from <glyphclass>;For example:
sub ampersand from [ampersand.1 ampersand.2];or ornament variations:
sub asterisk from [orn.1 orn.2 orn.3 orn.4];Context Dependent Substitutions»
A context-dependent rule can be any of the rules described above with one important difference: it defines a context that must include a target sequence of glyphs (or glyph classes).
In the simple form of, say, ligature substitution we simply write:
sub a b c by D;In context-dependent substitution we can declare that “abc”, which is a target sequence of glyphs for a ligature substitution rule, must be a part of a larger context:
sub period a' b' c' period by D;Only when “abc” is surrounded by two period glyphs will substitution take place. Note that we have marked the target glyphs with the single quote character positioned immediately after the glyph name.
The rule is specified as follows:
sub <marked glyph sequence> # Target sequence with marked glyphs
by <glyph sequence>; # Sub-run replacement sequence A <glyph sequence> comprises one or more glyphs or glyph classes.
<marked glyph sequence> is a <glyph sequence> in which a set of glyphs or glyph classes is identified, i.e. “marked”. We will call this marked set of glyphs a sub-run. A sub-run is marked by inserting a single quote (’) after each of its member elements.
This sub-run represents the target sequences of the lookups called by this rule. The lookup type of the lookup called by this rule is auto-detected from their target and replacement sequences in the same way as in their corresponding stand-alone (i.e. non-contextual) statements.
Example 1. This calls a lookup. The rule below means: in sequences a d or e d or n d, substitute d by d.alt.
sub [a e n] d' by d.alt;Example 2. This also calls a single substitution lookup. The rule below means: if a capital letter is followed by a small capital, then replace the small capital by its corresponding lowercase letter.
sub [A-Z] [a.smcp-z.smcp]' by [a-z];Example 3. This calls a ligature substitution lookup. The rule below means: in sequences e t c or e.init t c, substitute the first two glyphs by the ampersand.
sub [e e.init]' t' c by ampersand;Specifying Exceptions to the Context Rule»
Exceptions to a chaining contextual substitution rule are expressed by inserting a statement of the following form anywhere before the chaining contextual rule and in the same lookup as it:
ignore sub <marked glyph sequence> (, <marked glyph sequence>)*;The keywords ignore sub are followed by a comma-separated list of <marked glyph sequence>s. At most one sub-run of glyphs or glyph classes may be marked in each <marked glyph sequence>, by a single-quote (’) following each glyph or glyph class. This marked sub-run, when present, is taken to correspond to the “input sequence” of that rule. This generally means that it should correspond to the place where substitution would have occurred had the sequence not been an exception (see examples below). This is necessary for the OpenType layout engine to correctly handle skipping this sequence. When no glyphs are marked, then only the first glyph or glyph class is taken to be marked.
The ignore sub statement works by creating subtables in the GSUB that tell the OT layout engine simply to match the specified sequences, and not to perform any substitutions on them. As a result of the match, remaining rules (i.e. subtables) in the lookup will be skipped.
Example 1. Ignoring specific sequences:
The ignore sub rule below specifies that the substitution in the sub rule should not occur for the sequences f a d, f e d, or a d d. Note that the marked glyphs in the exception sequences indicate where a substitution would have occurred; this is necessary for the OpenType layout engine to correctly handle skipping this sequence.
ignore sub f [a e] d', a d' d;
sub [a e n] d' by d.alt;Example 2. Matching a beginning-of-word boundary:
ignore sub @LETTER f' i';
sub f' i' by f_i.init;The example above shows how a ligature may be substituted at a word boundary. @LETTER must be defined to include all glyphs considered to be part of a word. The substitute statement will get applied only if the sequence doesn’t match @LETTER f i; that is only at the beginning of a word.
Example 3. Matching a whole word boundary:
ignore sub @LETTER a' n' d', a' n' d' @LETTER;
sub a' n' d' by a_n_d;In this example, the a_n_d ligature will apply only if the sequence a n d is neither preceded nor succeeded by a member of the @LETTER class.
Example 4. This shows a specification for the contextual swashes feature:
feature cswh {
# --- Glyph classes used in this feature:
@BEGINNINGS = [A-N P-Z Th m];
@BEGINNINGS_SWASH = [A.swsh-N.swsh P.swsh-Z.swsh T_h.swsh m.init];
@ENDINGS = [a e z];
@ENDINGS_SWASH = [a.fina e.fina z.fina];
# --- Beginning-of-word swashes:
ignore sub @LETTER @BEGINNINGS';
sub @BEGINNINGS' by @BEGINNINGS_SWASH;
# --- End-of-word swashes:
ignore sub @ENDINGS' @LETTER;
sub @ENDINGS' by @ENDINGS_SWASH;
} cswh;If a feature by definition targets only glyphs at the beginning or ending of a word, such as the init and fina features, then the application is expected to be responsible for detecting the relevant word boundary; the feature itself can be simply defined as the appropriate substitutions, without regard for word boundary.
Positioning Lookups»
The OpenType specification allows you to define many positioning lookups. The lookup types may be separated into three groups:
-
Basic lookups, single and pair positioning:
-
The Cursive attachment lookup that allows smooth connection of script and cursive glyphs:

-
Mark attachment lookups that define relative positions of glyphs and marks:

FontLab VI supports all groups of lookups.
As in the case with substitution, positioning lookups may be context-free and context-dependent. Context-dependent lookups are the same as context-free but add a context that is verified against the source sequence of glyphs. Only when the context is matched positioning is performed.
Please note that glyph positioning is performed after substitution and that all positioning lookups must be defined for the glyph string that is a result of substitution.
Glyph positioning rules begin with the keyword pos; instead of pos, the longer keyword position may also be used. (The enum or ignore keywords may precede the pos keyword in some cases.) The GPOS lookup type is auto-detected from the format of the rest of the rule.
Glyph Geometry»
Positioning lookups may change one of the glyph positioning metrics:

A single positioning lookup may tweak any of four values: placement_X, placement_Y, advance_Y and advance_Y.
Modification of the origin point of the glyph will shift it and all following glyphs. Modification of the advance vector will shift the next glyph in the glyph string.
Value Record»
A <valuerecord> is used in positioning rules to define offsets to shift glyph origin or advance vector. It must be enclosed by angle brackets, except for format A, in which the angle brackets are optional. Note that the <metric> adjustments indicate values (in design units) to add to (positive values) or subtract from (negative values) the placement and advance values provided in the font (in the hmtx and vmtx tables).
Value record format A:
< <metric> > # Angle brackets are optionalHere the <metric> represents an X advance adjustment, except when used in the vkrn feature, in which case it represents a Y advance adjustment. All other adjustments are implicitly set to 0. This is the simplest feature file <valuerecord> format, and is provided since it represents the most commonly used adjustment (i.e. for kerning). For example:
-3 # without <>
<-3> # with <>Value record format B:
< <metric> <metric> <metric> <metric> >Here, the <metric>s represent adjustments for X placement, Y placement, X advance, and Y advance, in that order. For example:
<-80 0 -160 0> # X placement adj: -80; X advance adj: -160Single Positioning»
A Single Pos rule is specified as:
pos <glyph|glyphclass> <valuerecord>;Here, the <glyph|glyphclass> is adjusted by the <valuerecord>. For example, to reduce the left and right sidebearings of a glyph each by 80 design units:
pos one <-80 0 -160 0>;To shift the glyph up by 100 units:
position A <0 100 0 -100>;Note that we changed the placement by 100 units but compensated for that with a -100 change applied to advance. This is needed to shift only the current glyph and not the following glyphs in the string.
Pair Positioning»
Rules for this lookup type are usually used for kerning and must follow this format:
pos <glyph|glyphclass> <glyph|glyphclass> <valuerecord format A>; This format is provided since it closely parallels the way kerning is expressed in a plain pair kerning table. Here, the <valuerecord> must be of value record format A only, and corresponds to the first <glyph|glyphclass>.
Kerning can most easily be expressed with this format. This will result in adjusting the first glyph’s X advance, except when in the vrkn feature, in which case it will adjust the first glyph’s Y advance. Some examples:
pos T a -100; # specific pair (no glyph class present)
pos [T] a -100; # class pair (singleton glyph class present)
pos T @a -100; # class pair (glyph class present, even if singleton)
pos @T [a o u] -80; # class pairNote that if at least one glyph class is present (even if it is a singleton glyph class), then the rule is interpreted as a class pair; otherwise, the rule is interpreted as a specific pair.
In the kern feature, the specific glyph pairs will typically precede the glyph class pairs in the feature file, mirroring the way that they will be stored in the font.
feature kern {
# specific pairs for all scripts
# class pairs for all scripts
} kern;Enumerating Pairs»
If some specific pairs are more conveniently represented as a class pair, but the editor does not want the pairs to be in a class kerning subtable, then the class pair must be preceded by the keyword enum (or its longer variant enumerate). The implementation software will enumerate such pairs as specific pairs. Thus, these pairs can be thought of as “class exceptions” to class pairs. For example:
@Y_LC = [y yacute ydieresis];
@SMALL_PUNC = [comma semicolon period];
enum pos @Y_LC semicolon -80; # specific pairs
pos f quoteright 30; # specific pair
pos @Y_LC @SMALL_PUNC -100; # class pairThe enum rule above can be replaced by:
pos y semicolon -80;
pos yacute semicolon -80;
pos ydieresis semicolon -80;without changing the effect on the font.
Subtable Breaks»
The implementation software will insert a subtable break within a run of class pair rules if a single subtable cannot be created due to class overlap. A warning will be given. For example:
pos [Ygrave] [colon semicolon] -55; # [line 99] In first subtable
pos [Y Yacute] period -50; # [line 100] In first subtable
pos [Y Yacute Ygrave] period -60; # [line 101] In second subtablewill produce a warning that a new subtable has been started at line 101, and that some kern pairs within this subtable may never be accessed. The pair (Ygrave, period) will have a value of 0 if the above example comprised the entire lookup, since Ygrave is in the coverage (i.e. union of the first glyphs) of the first subtable.
Sometimes the class kerning subtable may get too large. The editor can force subtable breaks at appropriate points by inserting the statement:
subtable;between two class kerning rules. The new subtable created will still be in the same lookup, so the editor must ensure that the coverages of the subtables thus created do not overlap. For example:
pos [Y Yacute] period -50; # In first subtable
subtable; # Force a subtable break here
pos [A Aacute Agrave] quoteright -30; # In second subtableIf the subtable statement were not present, both rules would be represented within the same subtable.
Cursive attachment positioning»
A Cursive Pos rule is specified as:
pos cursive <glyph|glyphclass> <anchor> # Entry anchor
<anchor>; # Exit anchorThe first
For example, to define the entry point of glyph meem.medial to be at x=500, y=20, and the exit point to be at x=0, y=-20:
pos cursive meem.medial <anchor 500 20> <anchor 0 -20>;A glyph may have a defined entry point, exit point, or both. NULL anchor, must be used to indicate that an anchor is not defined:
position cursive meem.end <anchor 500 20> <anchor NULL >;Mark-to-Base attachment positioning»
A Mark-to-Base Pos rule is specified as:
pos base <glyph|glyphclass> # base glyph(s)
<anchor> mark <named mark glyphclass> + # anchor and mark glyph class
# repeated for each attachment point on the base glyphs(s) name
;Each <anchor> indicates the anchor point on the base glyph(s) to which the mark class’s anchor point should be attached.
A single Mark-To-Base statement must specify all the anchor points and their attaching mark classes.
This rule type does not actually support base glyph classes: the feature file syntax allows this in order to compactly specify Mark-To-Base rules for the set of glyphs which have the same anchor points. A feature file rule which uses a glyph class for the base glyph is expanded in the font to a separate rule for each glyph in the base class, although they will share the same anchor and mark class records.
The named mark glyph classes and the anchor points of all the mark glyphs in the named mark classes must have been previously defined in the feature file by markClass statements.
NOTE! The mark classes used within a single lookup must be disjointed: none may include a glyph which is in another mark class that is used within the same lookup.
For example, to specify that the anchor of mark glyphs acute and grave is at x=30, y=600, and that the anchor of mark glyphs dieresis and umlaut is at x=60, y=600, and to position the anchor point of the four mark glyphs at anchor point x=250, y=450 of glyphs a, e, o and u:
markClass [acute grave] <anchor 150 -10> @TOP_MARKS;
markClass [dieresis umlaut] <anchor 300 -10> @TOP_MARKS;
markClass [cedilla] <anchor 300 600> @BOTTOM_MARKS;
pos base [a e o u] <anchor 250 450> mark @TOP_MARKS
<anchor 250 -10> mark @BOTTOM_MARKS;All the base glyphs in a base glyph class must share the same anchor points for all mark classes, otherwise separate statements are needed.
pos base [e o] <anchor 250 450> mark @TOP_MARKS
<anchor 250 -12> mark @BOTTOM_MARKS;
pos base [a u] <anchor 265 450> mark @TOP_MARKS
<anchor 250 -10> mark @BOTTOM_MARKS;Mark-to-Ligature attachment positioning»
A Mark-to-Ligature Pos rule is specified as:
position ligature <ligature glyph|glyphclass> # ligature glyph or glyph class
<anchor> mark <named mark glyph class> + # anchor and named mark glyph class
# repeated for each anchor point on the first component glyph
# Start of anchor and mark info for the next ligature component.
ligComponent
<anchor> mark <named mark glyph class>
; # The block of ligComponent and its anchor-mark classes is repeated for each ligature component.The statement must specify all the anchor-mark class pairs for all the ligature components. It follows the form of the Mark-To-Base rule, except that a set of anchor-mark class pairs must be specified for each component glyph in the ligature. The set of anchor-mark class pairs for one component is separated for the set of the next component by the ligComponent keyword. If there are no anchor points on a component, it must still specify at least one anchor, which should be the NULL anchor. It is not required that each component have the same number of anchor points.
The named mark glyph classes and the anchor points of all the mark glyphs in the named mark classes must have been previously defined in the feature file by markClass statements.
An example of Mark-to-Ligature attachment positioning:
- Define mark anchors:
markClass sukun <anchor 261 488> @TOP_MARKS;
markClass kasratan <anchor 346 -98> @BOTTOM_MARKS;- Define mark-to-ligature rules:
pos ligature lam_meem_jeem
<anchor 625 1800> mark @TOP_MARKS # mark above lam
ligComponent # start specifying marks for meem
<anchor 376 -368> mark @BOTTOM_MARKS #mark below meem
ligComponent # start specifying marks for jeem
<anchor NULL> # jeem has no marks
;Note that a NULL anchor needs to be specified for a ligature component only when it has no non-NULL anchors. Otherwise, the implementation will supply a NULL anchor for each mark class that is not used by a ligature component.
If a glyph class is used, each ligature in the glyph class must have both the same number of components, and the same anchor positions on each component.
Mark-to-Mark attachment positioning»
A Mark-to-Mark Pos rule is specified as:
pos mark <glyph|glyphclass> # base mark glyph(s)
<anchor> mark <named mark glyphclass> + # anchor and mark glyph class
# repeated for each attachment point on the base glyphs(s) name
;This rule is distinguished from a Mark-to-Base Pos rule by the first “mark” keyword. Otherwise, it has the same syntax and restrictions.
An example of the Mark-to-Mark attachment positioning:
- Define name mark class:
markClass damma <anchor 189 -103> @MARK_CLASS_1;- Define mark-to-mark rule:
pos mark hanza <anchor 221 301> mark @MARK_CLASS_1;Specially handled features»
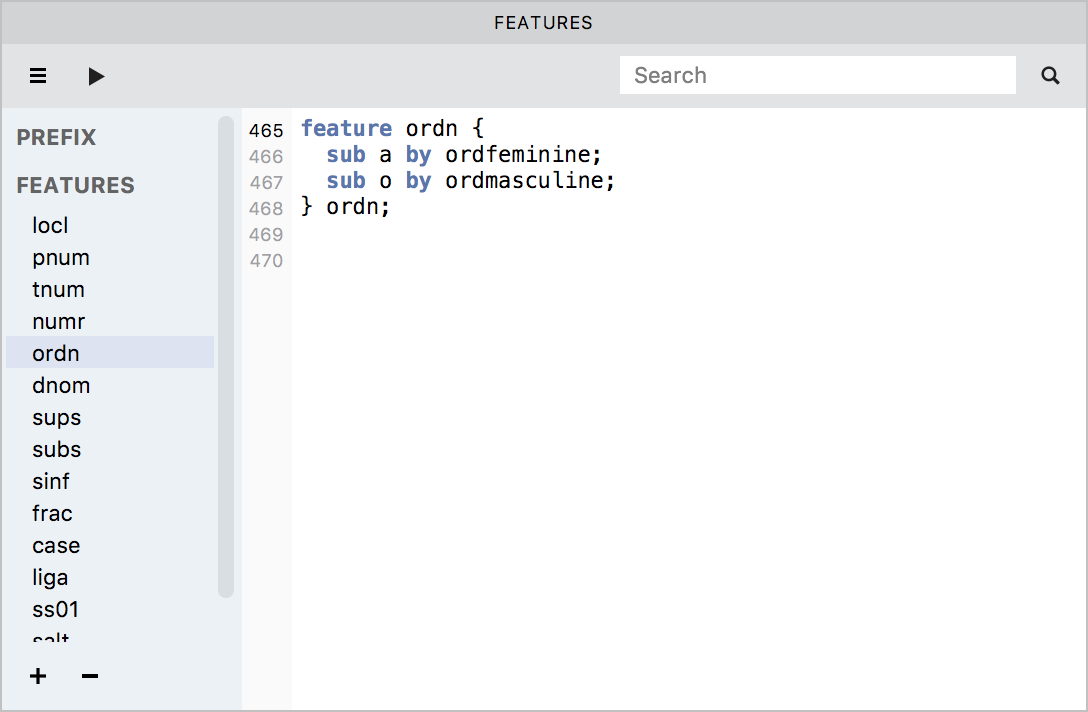
Descriptive names for Stylistic Set (’ss01 - ss20’) features»
Descriptive names are allowed for stylistic substitution features. These names are specified within a feature block for a Stylistic Set feature. The implementation will store the name strings in the “name” table, and will create a feature parameter data block which references them.
A single Stylistic Set feature block may contain more than one descriptive name in order to support different languages. These names are defined within a “featureNames” block that must be inside the stylistic set feature block, and must precede any of the rules in the feature. The syntax for a “featureNames” block is:
featureNames {
name < platform ID > < script ID > < language ID > < text string > ;
# This name entry is repeated for every script and language that you want to support.
} ;The syntax for the individual name string entries is similar to that of the name table nameID entries - the only difference is that the introductory keyword is ‘name’, and the name ID value is omitted, since the nameID value is auto-generated by the feature compiler.
Example:
feature ss01 {
featureNames {
name "Feature description for MS Platform, script Unicode, language English";
# With no platform ID, script ID, or language ID specified, the implementation assumes (3,1,0x409).
name 3 1 0x411 "Feature description for MS Platform, script Unicode, language Japanese";
name 1 "Feature description for Apple Platform, script Roman, language unspecified";
# With only the platform ID specified, the implementation assumes script and language = Latin. For Apple this is (1,0,0).
name 1 1 12 "Feature description for Apple Platform, script Japanese, language Japanese"; } ;
# --- rules for this feature ---
} ss01;